团队拓扑学
Hi,我是阿昌,今天学习记录的是关于团队拓扑学的内容。
看看最近这几年来新诞生的组织结构模型——团队拓扑学(Team Topologies)。
一、团队拓扑
尽管组件团队、特性团队和 Spotify 模型,都为团队的组成提供了不错的建议,但团队的类型应该是什么样并没有一致的标准。
如果所有团队都是特性团队,专注在某一个业务领域,那么业务领域开始变得复杂时,仍然僵化地专注于功能特性就会导致一些问题。
比如一个支付平台,它除了有源源不断的业务需求外,还有很多技术相关的事情要做,如数据的同步、分布式事务,或业务的回滚、对冲等。
假设按照系统的复杂度来判断,需要三十个人来维护这个平台,要是按照特性团队的思路来进行组织,就会分为三个特性团队,它们做着完全类似的业务开发。对于复杂的技术问题,就可能无人问津了。
尽管有了分会和协会可以一定程度上缓解,但这种自组织社区的执行力显然还不够。
这时,应该从团队优先(Team First)的角度去思考,将任务按照不同的复杂度来进行分解,并据此来创建团队。
比如对于高复杂度的任务,应该建立一个以解决这些问题为 KPI 的专门团队,只有这样的团队才能真正解决这些复杂的问题。
有时候会觉得,团队无法满足开发的需要,是因为成员的能力不行,因此重点对人进行赋能,增加他的内在认知负载。但其实有可能是团队结构不合理,导致外在认知负载过高。
Matthew Skelton 和 Manuel Pais 提出的团队拓扑学(Team Topologies),就从这一角度对团队的组成和沟通模式进行了大胆的尝试。
二、团队拓扑类型
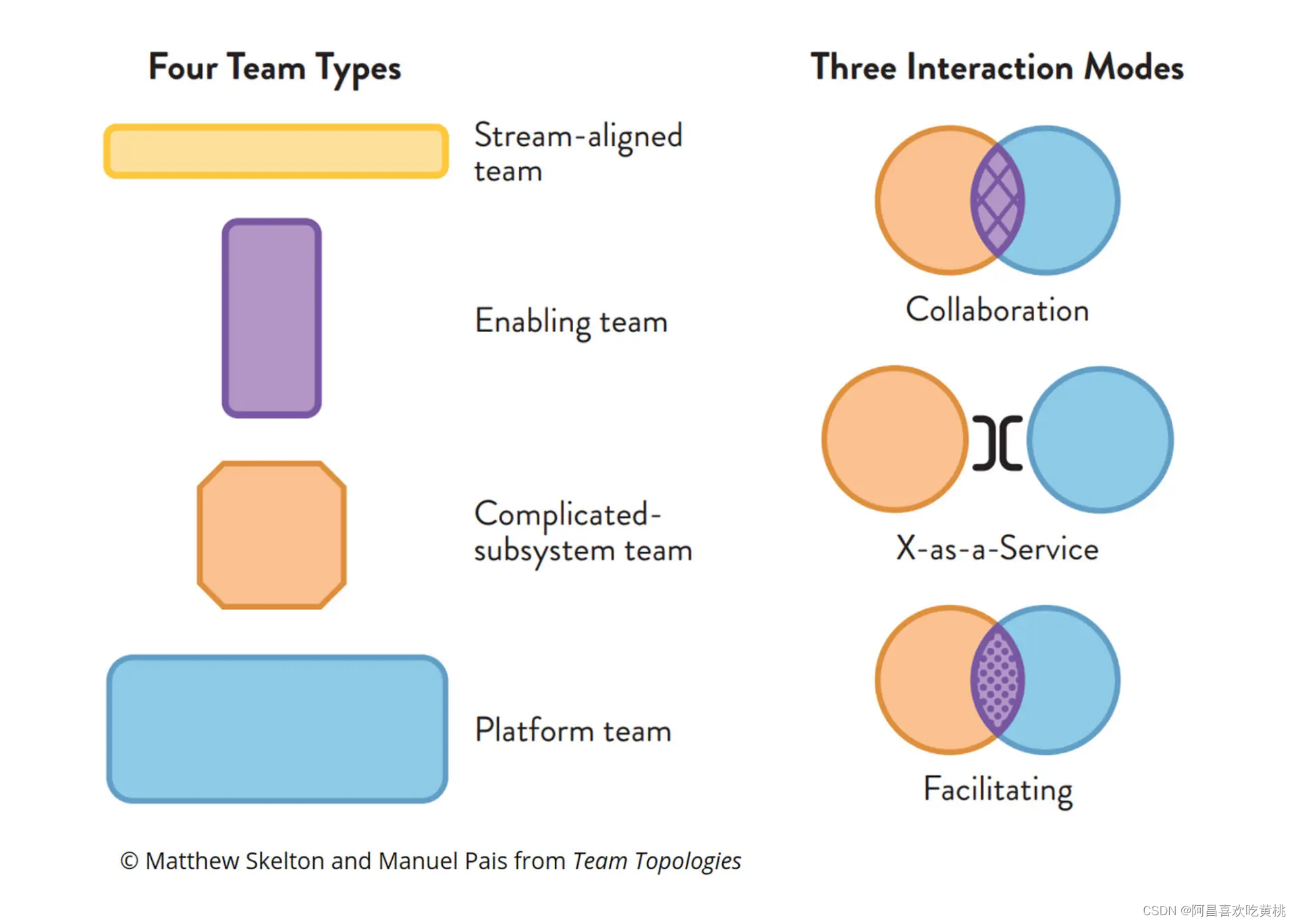
他们提出了四种团队拓扑类型和三种交互模式。
-
第一种团队拓扑类型是业务流团队(Stream-aligned Team),这里的“流”是指与
业务、领域或组织能力对齐的工作流程,业务流团队的工作有可能是一个产品或服务,也可能是一组特性、一个用户旅程或一个用户画像。他们有能力快速、安全、独立地构建和交付用户价值,而不用将部分工作交给其他团队。业务流团队是最主要的团队拓扑类型,你可以将它理解为特性团队,或 Spotify 中的小队,负责核心的价值交付。其他团队拓扑类型都是为了减轻业务流团队的负担,降低他们的认知负载而演进出来的。比如,一个遗留系统想做微服务拆分,这是一项高难度的架构迁移工作。业务流团队的成员每天处于高强度的交付压力之下,根本没有时间去调研、探索和学习。 -
这时候就诞生了第二种团队拓扑类型——赋能团队(Enabling Team),它由特定
技术领域或产品领域的专家组成。赋能团队里的这些专家可以开展调研,尝试不同的方案,寻找最佳实践。然后对业务流团队进行赋能,使他们不需要太多的努力,就能具备拆分微服务的能力,大大降低了认知负载。赋能团队并不会亲力亲为地解决具体技术问题,这些问题还是由业务流团队来处理。赋能团队主要关注的是,对组织中的所有业务流团队能力的提升。相比 Spotify 模型中的分会和协会等松散的技术社区,赋能团队的工作内容更聚焦,可以有效地帮助业务流团队,解决某方面能力欠缺的问题。不知道你的项目中是否有这样的模块,它的业务逻辑十分复杂,要想熟悉和理解需要极高的认知负载。比如视频的编解码、复杂的数学模型、语音识别算法等等。 -
这时通常的解决办法是,由该
领域的专家组成一个固定的团队,来维护这个复杂的模块。这种团队拓扑类型,就叫做复杂子系统团队(Complicated-Subsystem Team)。在遗留系统中,如果有些复杂的计算位于存储过程,转换成 Java 十分困难,而且效率也不一定高。这时候可以考虑把它整体隔离出去,构建一个复杂子系统,再相应去组建一个复杂子系统团队,专门来维护它。团队自己可以决定是保持不变,还是将存储过程慢慢演进成代码。
业务流团队在和复杂子系统交互时,只需要使用复杂子系统团队提供的 API,而不用费力地去理解这个复杂模块,同样可以降低认知负载。然而有的时候,业务流团队不止需要访问复杂的业务模块,还要和一些组织内部的基础设施打交道,比如 CI/CD 服务器、各种容器和中间件等。
- 比如一个刚刚做到持续构建的遗留系统,很可能持续集成服务器并不稳定,动不动就会挂掉,但业务流团队没有精力去解决这些问题。
这时候你需要的是第四种团队拓扑类型——平台团队(Platform Team)。它们负责解决底层问题,让业务流团队可以更专注于业务开发。
可以看到,团队拓扑的出发点是团队的认知负载,它所倡导的团队结构是认知负载最低的。它并没有尝试从不同的技术层面去解决团队的认知负载问题,这个角度仍然是在跨职能的业务流团队内部,通过不同的技术角色来解决的。因为业务流团队的成员虽然技术栈不同,但解决的都是价值流交付的问题。
团队拓扑建立了一个更高层次的抽象,按照技术和业务不同的复杂度,以及不同的团队目标来划分团队结构。
这是一种权衡。因为对个人来说,认知负载最低的一定是只从事自己最擅长的工作,也就是位于技术组件团队或职能团队中。但由于一个业务总是跨技术层级的,这就增加了沟通成本,导致了外在认知负载的升高;
另一方面,特性团队虽然能很好地解决沟通问题,但不同层级的技术问题仍然会增加他们的认知负载,使他们无法专注在业务交付上,身心俱疲。团队拓扑正是从这个角度,引入了另外三种团队类型,来解决特性团队的各种问题。
三、团队交互模式
这些团队之间是如何交互的呢?
团队拓扑学中给出了三种交互模式,分别是
- 协作
- 服务
- 促进

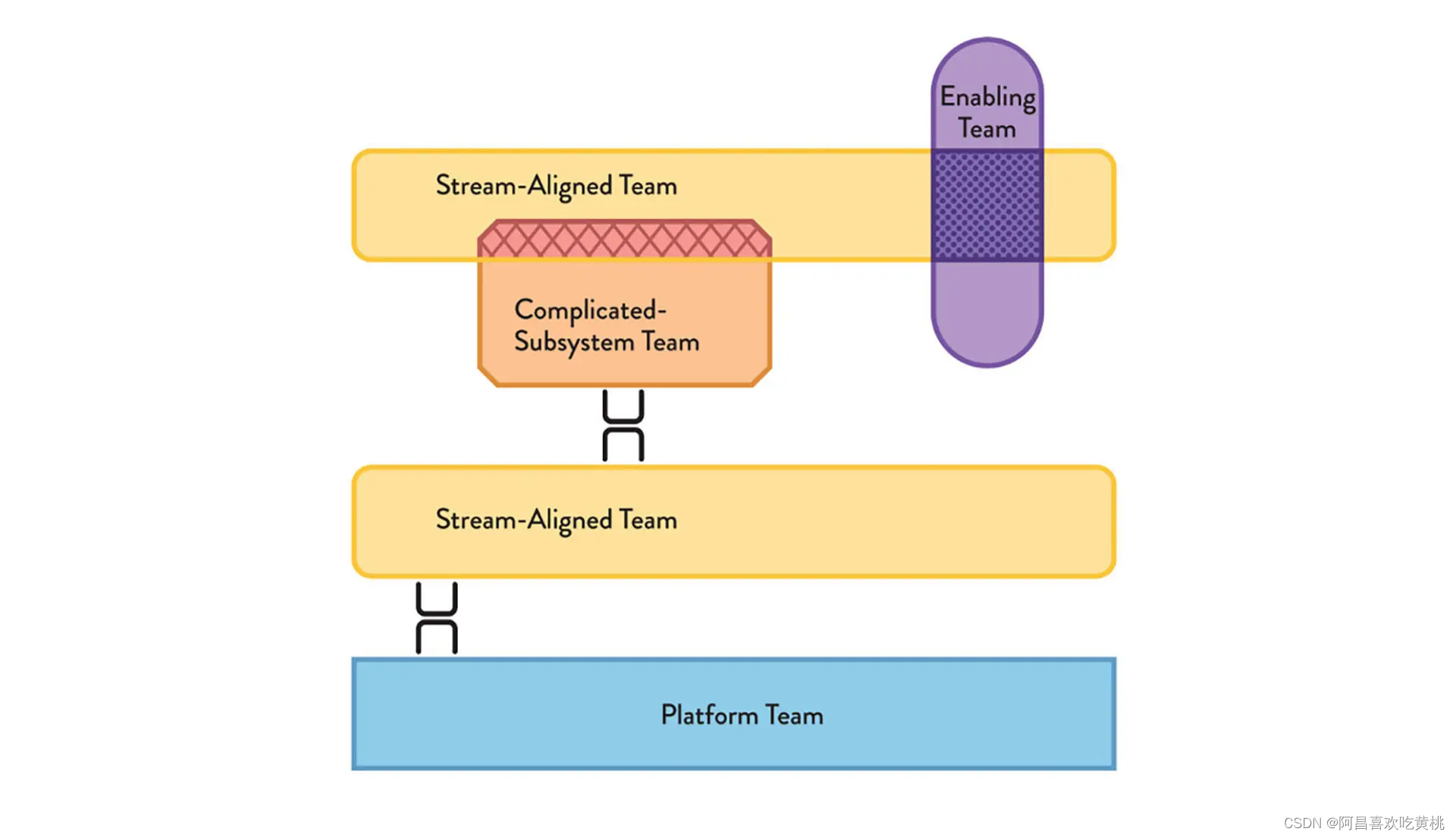
协作(Collaboration)是指一个团队与另一个团队紧密合作。比如前面提到的,业务流团队通过 API 来访问复杂子系统,当新的需求需要复杂子系统提供新的功能时,业务流团队就需要和复杂子系统团队通力合作,来完成这个需求;再比如一个用户登录功能,也需要业务流团队和平台团队的协作,业务流团队负责开发面向用户的界面和相应的后台,平台团队负责开发认证与鉴权功能,或者与其他单点登录系统集成。协作也会增加沟通成本,但这种成本是系统的复杂性所导致的,并不是像按技术分组那样,是人为因素导致的。
服务(X-as-a-Service)是指使用或提供某种服务,而尽量减少协作。比如如果复杂子系统已经提供了完成需求所用的 API,业务流团队就无需与复杂子系统团队协作;如果平台团队已经封装好了用户认证和鉴权的所有功能,业务流团队也只需要“拿来主义”即可。由于 API 或服务开箱即用,业务流团队无需关注底层的实现细节,就可以快速地实现功能。
促进(Facilitating)是指帮助其他团队清除障碍。这是赋能团队主要的交互模式,他们对外部团队提供支持和赋能,来提升他们的生产力和效率。
四、逆康威定律
适合遗留系统的团队结构到底是什么样的呢?
前面提到了康威定律,即 团队的结构会影响到系统的架构。
假如系统包含四个团队,每个团队都包含前端和后端开发,而仅有一个 DBA 负责数据库变更。那么根据康威定律,得到的软件架构一定是,拥有四个独立的应用,包含各自独立的用户界面和服务端,而它们共享一个单体数据库。
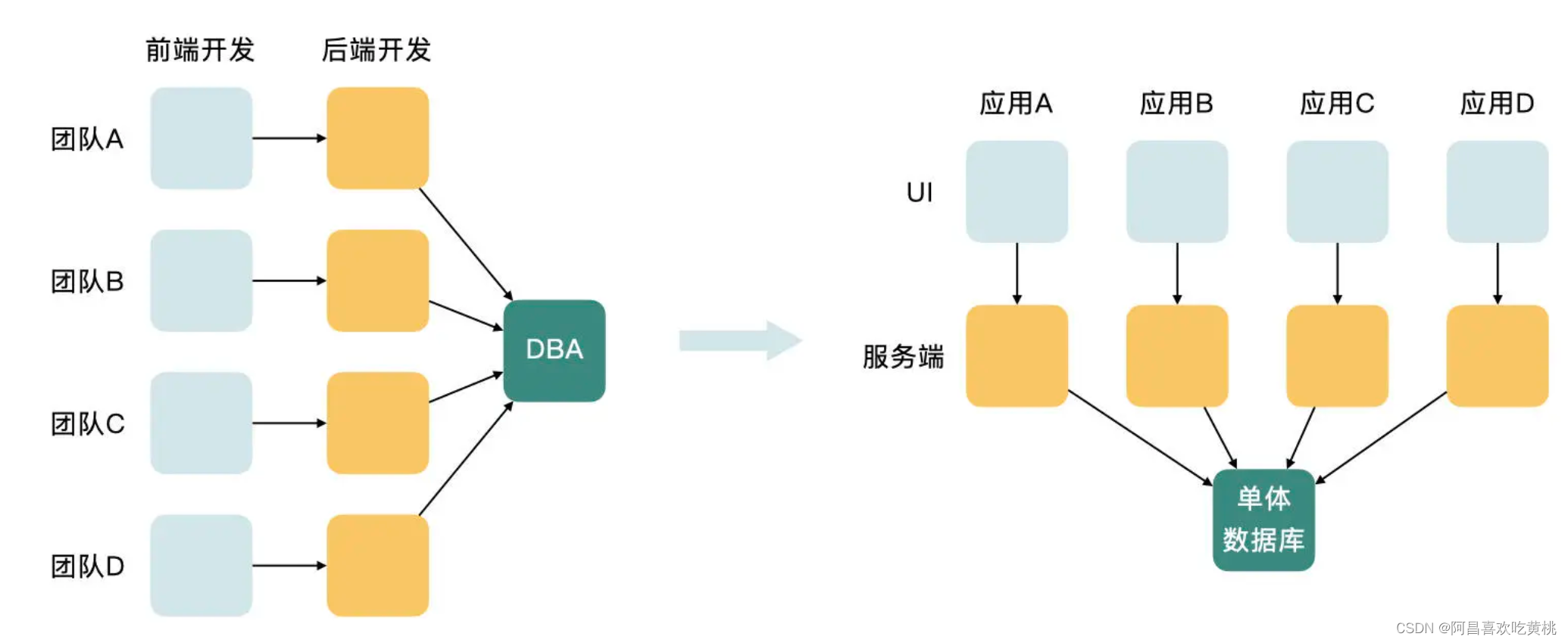
如果在保持团队结构不变的情况下,企图拆分数据库,一定是办不到的。即使勉强拆分出来,也会很快腐化。
正确的做法应该是,顺应康威定律,为每个团队配备一名 DBA,然后再拆分数据库。
每个应用的数据库由单独的 DBA 去维护,才能保证它不会腐化。这种为得到理想的架构而改变团队结构的做法,叫做逆康威定律(Inverse Conway Maneuver)。
也就是说,想得到什么样的架构,就先把组织结构调整成那个样子,以此来推动组织变革。
在遗留系统中,需要根据自己的目标架构来调整组织结构,同时参考特性团队、Spotify 模型和团队拓扑。
很多架构师在做方案时,总是期望一步到位,这样会给原本简单的方案带来很多复杂度。
更合理的方式应该是,先用简单的方式 run 起来,尽早上线去交付价值,等发现问题再去修补和演进。
这样更符合增量演进的原则,也更容易得到一个“刚刚好的架构”。
而“一步到位”的想法则更容易导致过度设计。产生“一步到位”这种想法的根本原因是什么?
表面上,是架构师在做设计的时候可能不会想到那么多,只是一种先入为主或者说习惯的想法,但实际上背后可能隐藏着康威定律。
如果有一个独立的团队去维护一个服务,这个团队能有足够的人力、有足够的上下文去守护这个服务的架构,就会更倾向于构建一个可演进的架构。
但如果团队接下来有哪些人不确定,他们有没有能力演进同样不确定,那么主观上我们就会不自觉地倾向一步到位式的设计。因为如果现在不做,以后就可能没机会了。如果是项目的负责人,希望能够主动改变团队的结构,以得到理想中的架构,并且潜移默化地改变团队中的各项技术决策。
五、总结
一种全新的团队结构模型——团队拓扑学。
所以在它后面加了一个“学”字,是因为它相比特性团队和 Spotify 模型,更接近一门学问。
它提出的团队认知负载和团队优先的理念,更是超前于这个时代。
组件团队、特性团队、Spotify 模型或团队拓扑,它们并不是相互替换的关系,而是可以按需合并和剪裁的。
它们面向的问题域不同、目标不同、出发点不同,因此不存在谁比谁高明的情况。
一张表格,总结几种讲过的团队类型,做个参考。
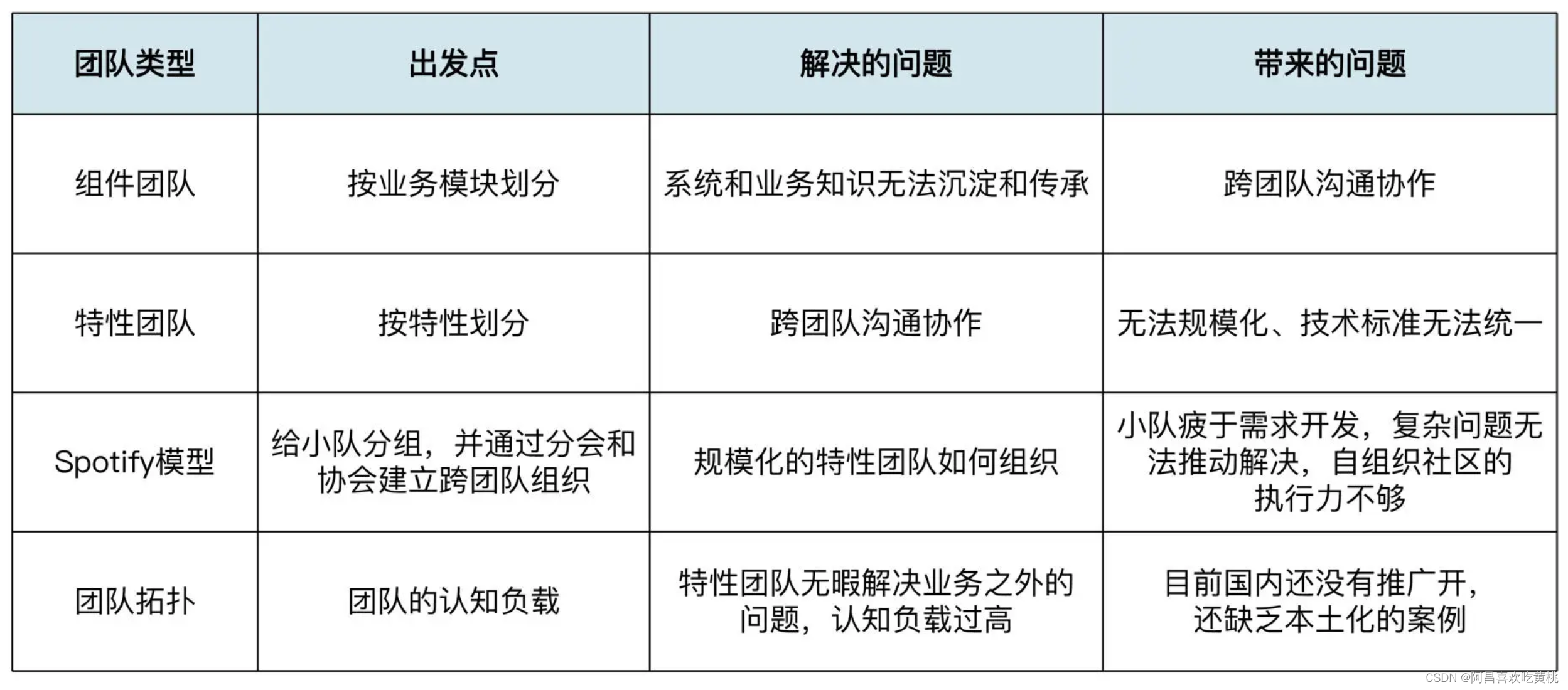
应该根据自己团队的实际问题,找出合适的方案。
比如可以以特性团队为基础,并为几个特性团队配备平台团队和赋能团队,这样的几个团队组成一个部落,同时也有跨团队的各种技术社区。比如很多组织的开发团队忙于需求开发,根本没有时间思考流程改进。
这时候想推动类似主干开发这类实践,是很难有进展的,因为它需要很多配套的基础设施,开发团队没有时间去做这些。
业务部门也只要看到需求上线就行,根本不关心流程改进,毕竟开发的痛点跟他们没关系。业务方总是把开发团队当成工具人,而不是合作者。
现在很多大厂开始组建工程效能部门,负责开发工具、优化流程、改进基础设施,一定程度上解放了开发部门。
虽然很难说这种工程效能部门是属于赋能团队还是平台团队,但至少都是在解决业务流团队平时没时间解决的痛点问题,为他们服务。
这就是一种非常有价值的探索。同时要记住的是,团队结构也要不断演进。虽然以不变应万变很酷,但当“应付”不了的时候,还是应当“应变”。
因为业务在变化,架构自然需要跟着变化以支撑业务,那么根据逆康威定律,也要调整团队结构,以支撑新的架构。